Practical Bazel: Part 1
Bazel is a great build system, which can accelerate the development of large-scale software. It practices the principle of trading space for time by caching the results of expensive build computation.
This article won’t cover what it is or how it works in detail. Instead, I will demonstrate how to get started with Bazel quickly with extremely simple code. We don’t need the Java or C++ rules of bazel. For this article, we will mainly use shell scripts to mock compilers.
Install bazelisk
Bazelisk (https://github.com/bazelbuild/bazelisk.git) is a launcher for Bazel which can handle different versions of Bazel.
After installing it, we only need to specify the version of Bazel we want to use in the .bazelversion file of the project root.
Create workspace
We can create a new directory with any name and create a new Bazel workspace (a WORKSPACE file) in it.
$ mkdir practical-bazel-1
$ cd practical-bazel-1
$ touch WORKSPACE
After that, we can test whether bazelisk would work:
$ bazel build
Starting local Bazel server and connecting to it...
WARNING: Usage: bazel build <options> <targets>.
Invoke `bazel help build` for full description of usage and options.
Your request is correct, but requested an empty set of targets. Nothing will be built.
INFO: Analyzed 0 targets (0 packages loaded, 0 targets configured).
INFO: Found 0 targets...
INFO: Elapsed time: 1.578s, Critical Path: 0.01s
INFO: 1 process: 1 internal.
INFO: Build completed successfully, 1 total action
Create a simple build rule
The next step is to create a BUILD file and add a simple genrule in it:
$ touch BUILD
in this BUILD file
genrule(
name = 'hello',
outs = ['hello.txt'],
cmd = 'echo "Hello World" > $@',
)
You could infer that the $@ is the output file name, which is hello.txt in this context. genrule means the rule that generates files, using bash or other supported shells. In this shell, it doesn’t matter what you execute. You can even use wget or curl to download a file remotely. But it is not recommended since the output is not guaranteed to be the same (for more details, please read Hermeticity).
To test this build rule:
$ bazel build //:hello
Why we need Bazel
The build looks pretty fast in the example above. So why we need Bazel?
Here’s a minimal example. If you add a new block to the BUILD file:
genrule(
name = 'hello-slow',
outs = ['hello-slow.txt'],
cmd = 'sleep 5; echo "Hello World" > $@',
)
Without build cache, bazel build //:hello-slow will always take 5 seconds to execute. But if we use Bazel with build cache, it will only take less than 1 second:
# This is the second time
$ bazel build //:hello-slow
INFO: Analyzed target //:hello-slow (1 packages loaded, 1 target configured).
INFO: Found 1 target...
Target //:hello-slow up-to-date:
bazel-bin/hello-slow.txt
INFO: Elapsed time: 0.055s, Critical Path: 0.00s
INFO: 1 process: 1 internal.
INFO: Build completed successfully, 1 total action
If you’d like to retry a clean build:
$ bazel clean --expunge
A bit into the real world
If you’re working on a real-world project, a shell command won’t be sufficient to build the product. The compiler would build the source code, and then the linker would link the object files together into a library or executable (binary or artifact). It is like:
$$ binary = Linker(Compiler(code)) $$
What Bazel is doing here is is nothing magic. It is like a wrapper with extra features (distributed cache, build cache, parallelism, etc.):
$$ binary = Bazel(Linker(Compiler(code))) $$
(Note: this is for quick understanding, not for accuracy.)
What will determine whether an existing build cache is valid? Bazel can compute the hash of the source code and use it as the cache key. If the hash is different, the cache will be invalid. Thus, a clean build will always be triggered.
Let’s make the example a bit more complex. We will include srcs to genrule:
genrule(
name = "hello-slow-dummy-srcs",
srcs = ["src/dummy-src.txt"],
outs = ["hello-slow-dummy-srcs.txt"],
cmd = "sleep 5; echo $$(cat src/dummy-src.txt) > $@",
)
We need to create the dummy-src.txt file:
$ mkdir src
$ touch dummy-src.txt
$ echo "content of dummy-src.txt" > dummy-src.txt
We can try it now:
$ bazel build //:hello-slow-dummy-srcs
For the first time, it would take 5 seconds. Then the second time, it would be much faster.
However, when you change the content of src/dummy-src.txt, it would be “slow” again.
This is basically how Bazel works locally.
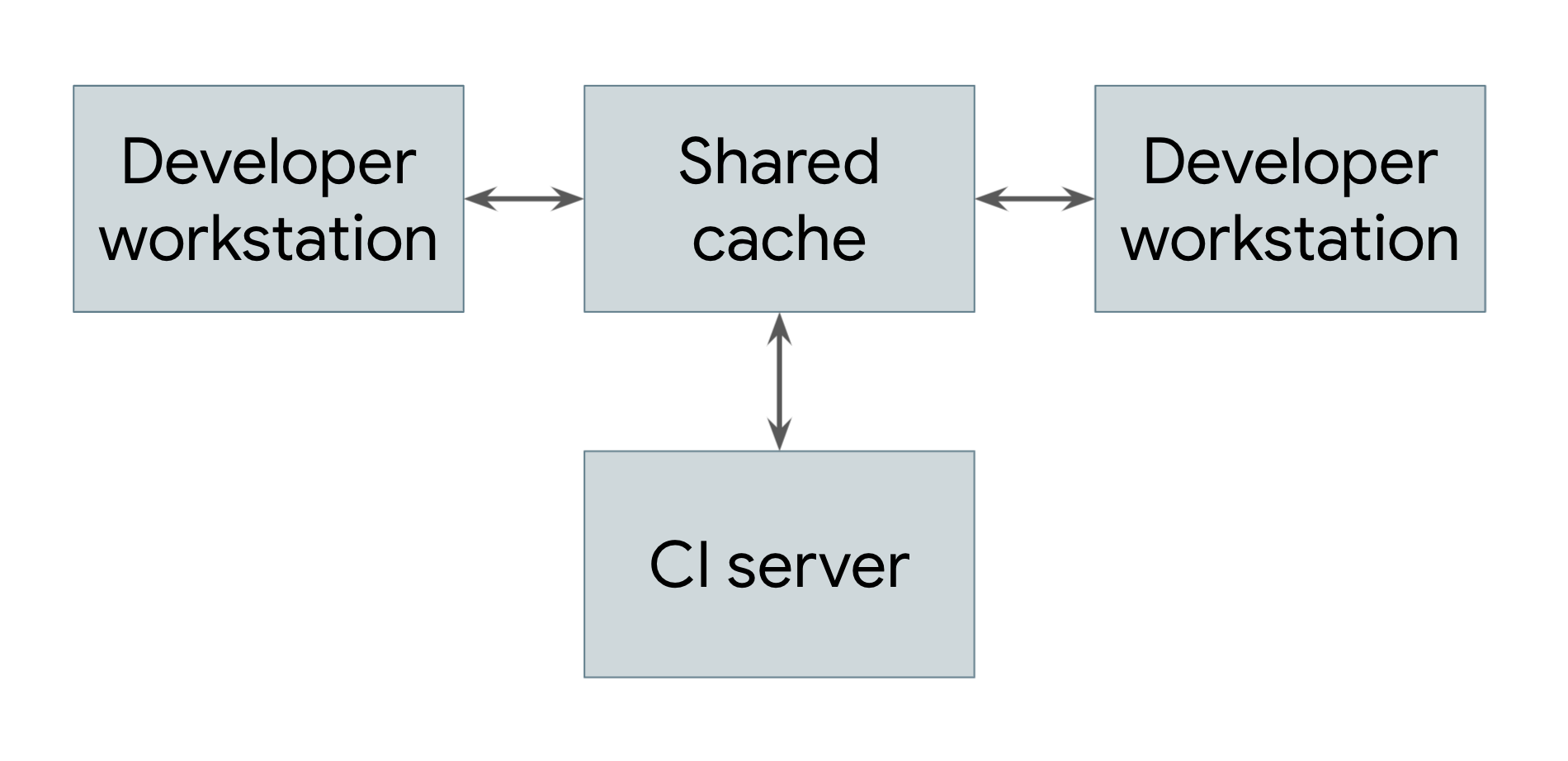
For a project with hundreds or thousands of modules, the clean build would be very slow. However, most commits or Pull Requests won’t change many of these modules. Bazel can cache these build results, with Remote Caching (https://bazel.build/docs/remote-caching). In this case, the incremental build will be much faster.
This picture from https://bazel.build/basics/distributed-builds demonstrates how it works in practice:
What can we go from here?
Bazel is a great tool and many teams in the industry use it. However, the learning curve is very steep. While applying Bazel in an existing large project, it is better to use a bottom-up approach. We can start by building the leaf nodes in our dependency graph.
In addition to Remote Caching, Bazel is also designed to build projects in a distributed manner. This means that the build will be distributed across multiple (inexpensive) machines. Bazel’s slogan is “{ Fast, Correct } — Choose two”. In fact, I believe we can “Choose Three”, Fast, Correct, Inexpensive.
You can find the source code of this article on this GitHub repository.